论文:Blood Flow Clustering and Applications in Virtual Stenting of Intracranial Aneurysms
作者:Steffen Oeltze, Dirk J. Lehmann, Alexander Kuhn, Gabor Janiga, Holger Theisel, and Bernhard Preim
发表会议:VIS 2014
本文试图使用聚类的方法和其可视化展示,用于分析基于病人个体数据的血液流CFD(computational fluid dynamics)模拟数据,以判定颅内肿瘤虚拟支架的效果。为了寻找最合适的聚类方法,本文定量分析了三种在流线型数据中常用的聚类方法和其变种。此外,本文还介绍了多种基于聚类的流概述可视化方法。最后,对这些方法进行了专家评估。

源数据是一系列流线。流线除几何特征(位置、走向)外,还包含医学属性,如血液流速等。
为了减少视觉混乱,获取其中包含的模式,需要对复杂的流线进行聚类。
聚类使用的相似度度量如下:
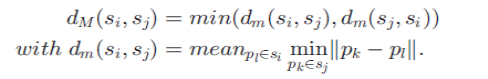
这样的度量方式更多的考虑线的走向而非长度,同时可以较好地处理异常值。
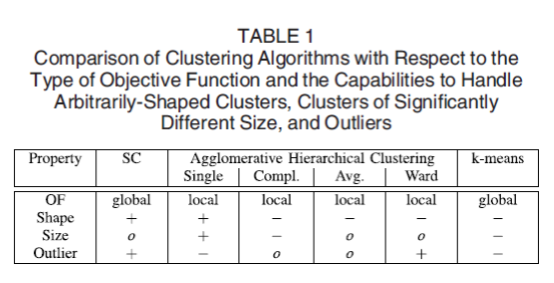
常见的流线聚类方法有k-means、AHC(agglomerative hierarchical clustering)和SC(spectral clustering),他们的特性如下表:
随后,通过定义一系列内在有效性度量,对不同的聚类方法进行定量分析:
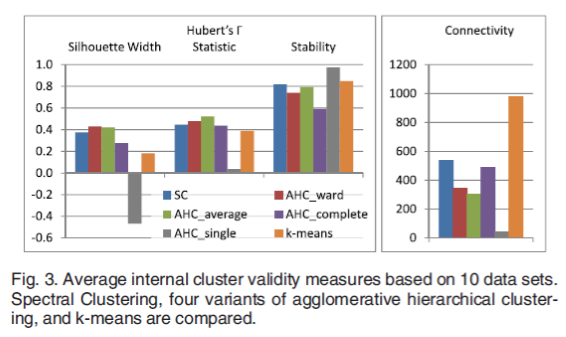
最终选择SC或使用complete link/ward’s method的AHC算法,其结果更加准确有效。
聚类的表达方法分为如下几种:
基于嵌入(embedding)
基于距离
基于密度
基于属性
最终选择综合考虑几种方案,用户可以设置不同参考的权重。
专家的反馈结果与之前的分析结果类似,说明这样的表达方式是合适的。
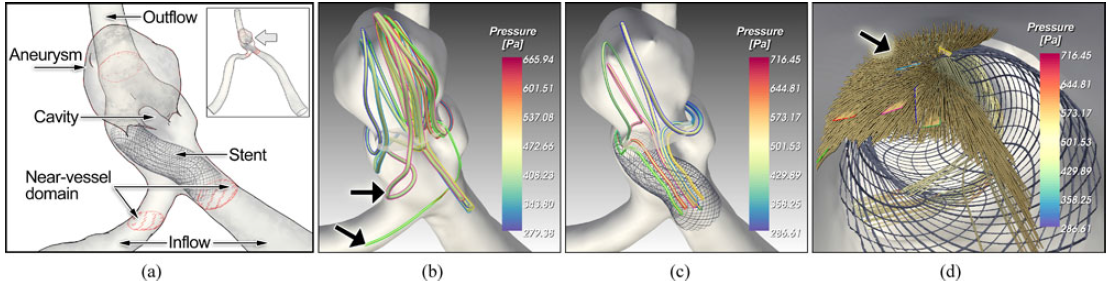
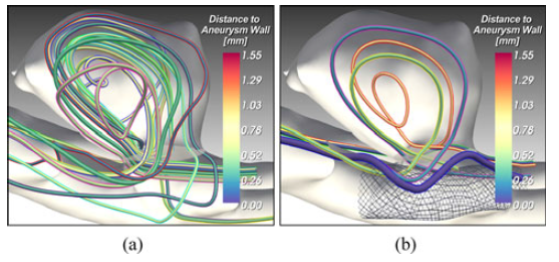
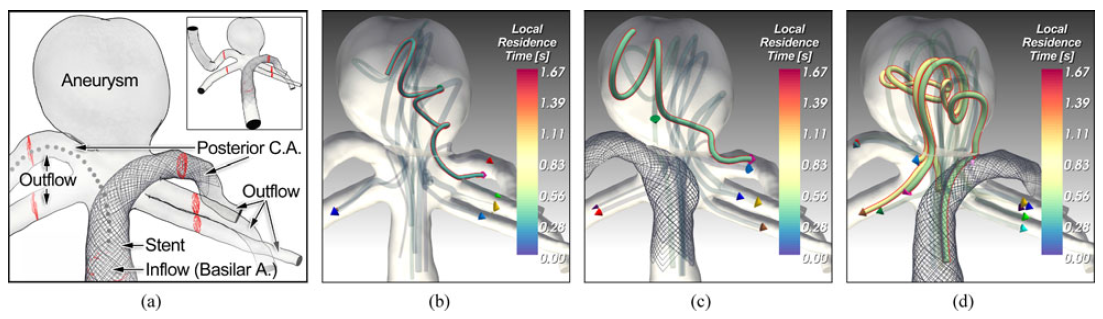
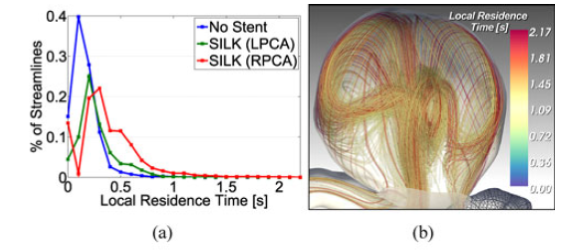
一些聚类可视化结果:
✉️ zjuvis@cad.zju.edu.cn